篇首语:本文由编程笔记#小编为大家整理,主要介绍了Python Selenium.WebDriver 对COOKIEs的处理及应用『模拟登录』相关的知识,希望对你有一定的参考价值。
COOKIE(复数形态:COOKIEs),又称“小甜饼”,为小型文本文件。某些网站为了辨别用户身份而储存在用户本地终端(Client Side)上的数据(通常经过加密),COOKIE保存在客户端中,按在客户端中的存储位置,可分为 内存COOKIE和硬盘COOKIE
内存 COOKIE 由浏览器维护,浏览器关闭即消失,存在时间短暂。硬盘COOKIE保存在硬盘里,除非用户手动清理或到了过期时间,硬盘COOKIE不会清除,存在时间较长。所以,按存在时间,可分为非持久COOKIE和持久COOKIE
COOKIE的典型应用场景
COOKIE对于爬虫来说是比较常用到的,一般随着爬虫请求发送,是实现反反爬的参数之一
我使用的是 Edge 浏览器,但 Chrome 浏览器其实也差不多一样。以百度首页为例,打开调试工具(F12),点击Application(应用程序),选择 Storage 下的 COOKIEs 选项,找到当前网页即可看到所有的 COOKIE
可以发现的是,COOKIE在浏览器中是一条一条存在的,每条COOKIE都是一个键值对的结构


Selenium 能够实现操作浏览器的COOKIE,因为本身就是其调用浏览器运行,能操作的内容有对COOKIE的读取、新增和删除
1)、读取COOKIE
读取COOKIE有两种方法,分别是 driver.get_COOKIEs() 和 driver.get_COOKIE(name)
从方法名上来看一个带s一个不带s,功能上看带s的是获取所有的COOKIE对象,不带s的是获取指定的单条COOKIE
driver.get_COOKIEs() 能够获取所有的COOKIE,并以 列表 形式返回所有COOKIE
演示代码:👇
from selenium import webdriver
browser = webdriver.Edge(executable_path=r"msedgedriver.exe")
browser.get("https://www.baidu.com/")
print(browser.get_COOKIEs())
['domain': '.baidu.com', 'expiry': 1629821019, 'httpOnly': False, 'name': 'BA_HECTOR', 'path': '/', 'secure': False, 'value': '8s818la521202160bp1gia2ic0r', 'domain': '.baidu.com', 'httpOnly': False, 'name': 'H_PS_PSSID', 'path': '/', 'secure': False, 'value': '34437_34441_31254_33848_34072_34092_34106_26350_34416_34390', 'domain': '.baidu.com', 'expiry': 1661353419, 'httpOnly': False, 'name': 'BAIDUID', 'path': '/', 'secure': False, 'value': 'EDB65890D2F1E97267AD56A70D8F24E8:FG=1', 'domain': '.baidu.com', 'expiry': 3777301066, 'httpOnly': False, 'name': 'BIDUPSID', 'path': '/', 'secure': False, 'value': 'EDB65890D2F1E972DC3D6A6A8114E431', 'domain': '.baidu.com', 'expiry': 3777301066, 'httpOnly': False, 'name': 'PSTM', 'path': '/', 'secure': False, 'value': '1629817419', 'domain': 'www.baidu.com', 'expiry': 1630681419, 'httpOnly': False, 'name': 'BD_UPN', 'path': '/', 'secure': False, 'value': '12314753', 'domain': 'www.baidu.com', 'httpOnly': False, 'name': 'BD_HOME', 'path': '/', 'secure': False, 'value': '1']
driver.get_COOKIE(name) 根据名称获取单个COOKIE
源码:
对于.get_COOKIE(name)方法,咱们可以先去扩展一下去看源码,无非就是先用.get_COOKIEs()方法获取所有的COOKIE,再通过循环判断提取目标COOKIE
def get_COOKIE(self, name):
"""
Get a single COOKIE by name. Returns the COOKIE if found, None if not.
:Usage:
driver.get_COOKIE('my_COOKIE')
"""
if self.w3c:
try:
return self.execute(Command.GET_COOKIE, 'name': name)['value']
except NoSuchCOOKIEException:
return None
else:
COOKIEs = self.get_COOKIEs()
for COOKIE in COOKIEs:
if COOKIE['name'] == name:
return COOKIE
return None
演示代码:👇
获取百度首页名为BD_HOME的COOKIE内容,并将其输出
from selenium import webdriver
browser = webdriver.Edge(executable_path=r"msedgedriver.exe")
browser.get("https://www.baidu.com/")
print(browser.get_COOKIE("BD_HOME"))
'domain': 'www.baidu.com', 'httpOnly': False, 'name': 'BD_HOME', 'path': '/', 'secure': False, 'value': '1'
2)、新增COOKIE
新增COOKIE只有一个方法,那就是driver.add_COOKIE(COOKIE_dict),根据 二、COOKIE在浏览器中的形式结构 可以得知COOKIE是一个键值对数据,传入的COOKIE对象中必须包含name和value两个属性,缺少其中任何一个都会添加失败。除此之外还有四个可选属性,分别为path,domain,secure,expiry
源码:
让咱们先来看看源码,源码中就有对 属性值的描述注释,还是值得去看的
def add_COOKIE(self, COOKIE_dict):
"""
Adds a COOKIE to your current session.
:Args:
- COOKIE_dict: A dictionary object, with required keys - "name" and "value";
optional keys - "path", "domain", "secure", "expiry"
Usage:
driver.add_COOKIE('name' : 'foo', 'value' : 'bar')
driver.add_COOKIE('name' : 'foo', 'value' : 'bar', 'path' : '/')
driver.add_COOKIE('name' : 'foo', 'value' : 'bar', 'path' : '/', 'secure':True)
"""
self.execute(Command.ADD_COOKIE, 'COOKIE': COOKIE_dict)
演示代码:👇
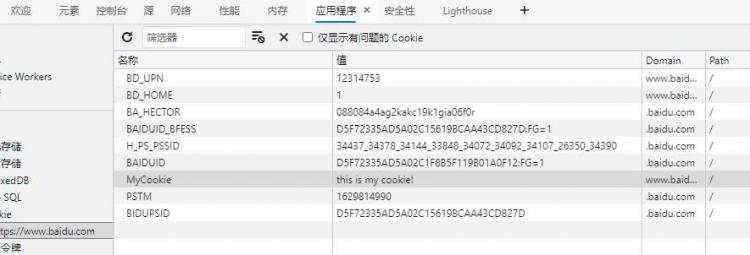
向其百度首页添加一个名为 MyCOOKIE 的COOKIE,其值为 this is my COOKIE!
from selenium import webdriver
browser = webdriver.Edge(executable_path=r"msedgedriver.exe")
browser.get("https://www.baidu.com/")
browser.add_COOKIE("name": "MyCOOKIE", "value": "this is my COOKIE!")
在打开的浏览器窗口,打开调试工具就能看到添加的COOKIE
3)、删除COOKIE
删除COOKIE与读取COOKIE类似,也有两个方法,分别是driver.delete_all_COOKIEs() 和 driver.delete_COOKIE(name),一个是全部删除,一个是删除其中一个,用法也于读取COOKIE一样
driver.delete_all_COOKIEs() 删除全部的COOKIE
演示代码:👇
from selenium import webdriver
browser = webdriver.Edge(executable_path=r"msedgedriver.exe")
browser.get("https://www.baidu.com/")
browser.delete_all_COOKIEs()
可以看到的是,百度首页在浏览器中的COOKIE已经全部被清空了 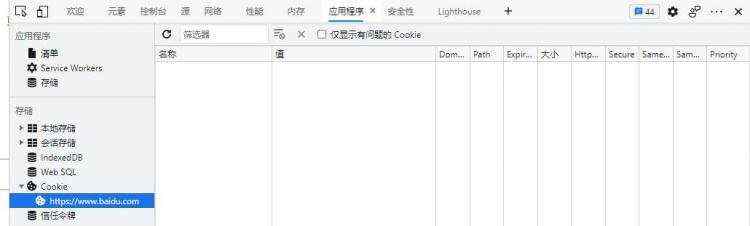
driver.delete_COOKIE(name) 删除指定名称的COOKIE
演示代码:👇
删除百度首页名为BD_HOME的COOKIE内容
from selenium import webdriver
browser = webdriver.Edge(executable_path=r"msedgedriver.exe")
browser.get("https://www.baidu.com/")
browser.delete_COOKIE("BD_HOME")
可以看到名为BD_HOME的COOKIE已经在浏览器中找不到了

在 爬虫领域 或 自动化测试中,总有一些网站只有登录后才能访问,或则某些数据只有在登录后才会出现。由于用户登陆后的身份信息通常会存放在COOKIE中,因此可以将登录后的COOKIE保存,再将此COOKIE添加到网页中来模拟已登录状态。能有效避免在登录页面中进行多次操作,即一次登录后即可保留登录状态
实现的步骤很简单,1. 只需要将当前页面中的COOKIE全部清空,2. 然后直接添加 已经在登录状态下 或 拥有身份信息 的COOKIE在网页中,3. 最后别忘记刷新一下网页driver.refresh,就可以实现页面保留登录状态的效果
步骤示例:👇
# 删除所有的COOKIEs
driver.delete_all_COOKIEs()
# 逐个添加COOKIE,可以使用循环
driver.add_COOKIE(COOKIE_dict)
driver.add_COOKIE(COOKIE_dict)
...
driver.refresh()
实际演示:👇🏻
还是以百度首页为例,实现流程:
需要注意的是,此代码为简单的百度首页登录,并未实现图片验证等自动验证功能,更多为参考意义,具体以实际为主
1)、让咱先来看看对百度首页的模拟登录
这里我使用的是Xpath定位
driver.find_element_by_xpath(xpath),当然也是可以使用其他的定位方式,如ID定位driver.find_element_by_id(id_)
由于存在百度首页登录时会出现验证的情况,代码并未对此进行自动验证处理,这时候就需要手动验证了
def handle_login(username, pwd, isverify=False):
"""
百度首页登录处理方法
:param username: 用户名
:param pwd: 用户密码
:param isverify: 是否存在网页验证
"""
# 点击右上角登录按钮
self.find_by_xpath(r"//a[@id='s-top-loginbtn']").click()
time.sleep(1)
# 点击用户名登录按钮
self.find_by_xpath(r"//p[@id='TANGRAM__PSP_11__footerULoginBtn']").click()
# 向输入框输入账户名
self.find_by_xpath(r"//input[@id='TANGRAM__PSP_11__userName']").send_keys(username)
# 向输入框输入密码
self.find_by_xpath(r"//input[@id='TANGRAM__PSP_11__password']").send_keys(pwd)
# 点击登录按钮
self.find_by_xpath(r"//input[@id='TANGRAM__PSP_11__submit']").click()
# 手动图形验证等待
input("请手动进行图形验证,完毕后输入任意内容继续运行")
if isverify:
# 点击发送验证码按钮
self.find_by_xpath(r"//input[@id='TANGRAM__29__button_send_mobile']").click()
# 等待用户输入手动验证码
vcode = input("请输入六位数验证码:")
self.find_by_xpath(r"//input[@id='TANGRAM__29__input_vcode']").send_keys(vcode)
# 点击确定按钮
self.find_by_xpath(r"//input[@id='TANGRAM__29__button_submit']").click()
2)、COOKIEs处理
需要可持久化存储COOKIE,以及对COOKIE进行读取并判断是否存在
简单写两个函数
def save_COOKIEs(data, encoding="utf-8"):
"""
百度首页COOKIEs保存方法
:param data: 所保存数据
:param encoding: 文件编码,默认utf-8
"""
with open(self.f_path, "w", encoding=encoding) as f_w:
json.dump(data, f_w)
def load_COOKIEs(encoding="utf-8"):
"""
百度首页COOKIEs读取方法
:param encoding: 文件编码,默认utf-8
"""
if os.path.isfile(self.f_path):
with open(self.f_path, "r", encoding=encoding) as f_r:
user_status = json.load(f_r)
return user_status
3)、使用COOKIE进行网页登录
根据刚开始的步骤示例,修改网页中的COOKIEs是很简单的
先将网页中原有的COOKIEs全部删除,然后通过循环一个个将保存的登录COOKIE全部添加进网页
def COOKIEs_login(COOKIEs: list):
"""
百度首页COOKIEs登录方法
:param COOKIEs: 网页所需要添加的COOKIE
"""
self.browser.delete_all_COOKIEs()
for c in COOKIEs:
self.browser.add_COOKIE(c)
self.browser.refresh()
4)、将上述流程总结写成一个对象
import os
import json
import time
from selenium import webdriver
class BaiduLogin:
def __init__(self, url, executable_path, f_path):
"""
对象初始化
:param url: 百度首页地址
:param executable_path: 浏览器驱动路径
:param f_path: COOKIEs文件保存路径
"""
self.url = url
self.browser = self.start_browser(executable_path)
self.f_path = f_path
@staticmethod
def start_browser(executable_path):
return webdriver.Edge(executable_path=executable_path)
def start_url(self):
self.browser.get(self.url)
def find_by_xpath(self, xpath):
return self.browser.find_element_by_xpath(xpath)
def baidu_login(self, *args):
self.start_url()
if COOKIEs := self.load_COOKIEs():
self.__COOKIEs_login(COOKIEs)
else:
self.__handle_login(*args, **kwargs)
def __handle_login(self, username, pwd, isverify=False):
"""
百度首页登录处理方法
:param username: 用户名
:param pwd: 用户密码
:param isverify: 是否存在网页验证
"""
# 点击右上角登录按钮
self.find_by_xpath(r"//a[@id='s-top-loginbtn']").click()
time.sleep(1)
# 点击用户名登录按钮
self.find_by_xpath(r"//p[@id='TANGRAM__PSP_11__footerULoginBtn']").click()
# 向输入框输入账户名
self.find_by_xpath(r"//input[@id='TANGRAM__PSP_11__userName']").send_keys(username)
# 向输入框输入密码
self.find_by_xpath(r"//input[@id='TANGRAM__PSP_11__password']").send_keys(pwd)
# 点击登录按钮
self.find_by_xpath(r"//input[@id='TANGRAM__PSP_11__submit']").click()
# 手动图形验证等待
input("请手动进行图形验证,完毕后输入任意内容继续运行")
if isverify:
time.sleep(1)
# 点击发送验证码按钮
self.find_by_xpath(r"//input[@id='TANGRAM__29__button_send_mobile']").click()
# 等待用户输入手动验证码
vcode = input("请输入六位数验证码:")
self.find_by_xpath(r"//input[@id='TANGRAM__29__input_vcode']").send_keys(vcode)
# 点击确定按钮
self.find_by_xpath(r"//input[@id='TANGRAM__29__button_submit']").click()
self.save_COOKIEs(self.browser.get_COOKIEs())
def __COOKIEs_login(self, COOKIEs: list):
"""
百度首页COOKIEs登录方法
:param COOKIEs: 网页所需要添加的COOKIE
"""
self.browser.delete_all_COOKIEs()
for c in COOKIEs:
self.browser.add_COOKIE(c)
self.browser.refresh()
def save_COOKIEs(self, data, encoding="utf-8"):
"""
百度首页COOKIEs保存方法
:param data: 所保存数据
:param encoding: 文件编码,默认utf-8
"""
with open(self.f_path, "w", encoding=encoding) as f_w:
json.dump(data, f_w)
def load_COOKIEs(self, encoding="utf-8"):
"""
百度首页COOKIEs读取方法
:param encoding: 文件编码,默认utf-8
"""
if os.path.isfile(self.f_path):
with open(self.f_path, "r", encoding=encoding) as f_r:
user_status = json.load(f_r)
return user_status
def quit(self):
# 关闭浏览器
self.browser.quit()
调用:👇
target_driver = "msedgedriver.exe"
url, COOKIE_fname = r"https://www.baidu.com/", "百度登录COOKIEs.json"
login = BaiduLogin(url, target_driver, COOKIE_fname)
login.baidu_login("用户名", "用户密码")
在使用requests请求之前,我们得先知道对于requests来说是怎么使用COOKIE
以百度首页为例,打开调试工具(F12),点击Network(网络\\抓包工具),如果空白的话就按Ctrl + R 快捷键刷新网页读取,找到位于第一个的请求www.baidu.com,选择Headers(标头)后在下方就能看到咱们对于https://www.baidu.com/这个链接的Request Headers(请求头),在里面就能找到COOKIE属性
但信心的朋友会发现在这里的COOKIE格式与我们在Application(应用程序),选择 Storage 下的 COOKIEs 选项看到的完全不一样,但其实都是同一些COOKIEs数据,将两者放在一起进行仔细比较还是能发现共同点的
对于请求头来说,需要的只有name和value,这也是为什么在 三、Selenium对COOKIE的操作 新增COOKIE中讲到 传入的COOKIE对象中必须包含name和value两个属性,两者以=号拼接,每一个COOKIE以;进行分割


在requests来说,使用COOKIE常用的有两种方式:
requests.get 或 requests.post 方法中传入COOKIEs参数
为了便于演示,会将requests返回的页面源码保存到html文件中进行展示
1)、通过请求头方式
在使用请求头方式时,想要事先将COOKIEs处理成与 图 5.1 中那样的格式,通过循环就能搞定,这没什么难度
预处理COOKIEs格式:
def COOKIE_handle(COOKIEs: list):
"""
COOKIEs 标头格式化处理函数
:param COOKIEs: selenium获取的COOKIEs
"""
COOKIEs = [f"i['name']=i['value']" for i in COOKIEs]
return "; ".join(COOKIEs)
使用requests发送请求:
import os
import json
import requests
def COOKIEs_load(path, encoding="utf-8"):
if os.path.isfile(path):
with open(path, "r", encoding=encoding) as f_r:
COOKIEs = json.load(f_r)
return COOKIEs
def COOKIE_handle(COOKIEs: list):
"""
COOKIEs 标头格式化处理函数
:param COOKIEs: selenium获取的COOKIEs
"""
COOKIEs = [f"i['name']=i['value']" for i in COOKIEs]
return "; ".join(COOKIEs)
def get_and_save(url, path, encoding="utf-8", **kwargs):
"""
使用requests对网址发送请求,并将请求结果存储
:param url: 网址
:param path: 存储文件路径
:param encoding: 文件编码,默认utf-8
"""
response = requests.get(url, **kwargs)
if response.ok:
response.encoding = encoding
with open(path, "w", encoding=encoding) as f_w:
f_w.write(response.text)
url = r"https://www.baidu.com/"
headers =
"User-Agent": (r"请使用自己的"
r"UA识别码"),
"COOKIE": COOKIE_handle(COOKIEs_load("百度登录COOKIEs.json"))
get_and_save(url, "baidu.html", headers=headers)
2)、使用COOKIEs参数
值得注意的是,传入的COOKIEs是一个字典,那么就需要对已有的COOKIEs数据进行处理,将其转化成requests能够识别的字典数据类型
预处理COOKIEs格式:
def COOKIE_handle(COOKIEs: list):
"""
COOKIEs 转化为字典函数
:param COOKIEs: selenium获取的COOKIEs
"""
dic =
for i in COOKIEs:
dic[i["name"]] = i["value"]
return dic
使用requests发送请求:
import os
import json
import requests
def COOKIEs_load(path, encoding="utf-8"):
if os.path.isfile(path):
with open(path, "r", encoding=encoding) as f_r:
COOKIEs = json.load(f_r)
return COOKIEs
def COOKIE_handle(COOKIEs: list):
"""
COOKIEs 转化为字典函数
:param COOKIEs: selenium获取的COOKIEs
"""
dic =
for i in COOKIEs:
dic[i["name"]] = i["value"]
return dic
def get_and_save(url, path, encoding="utf-8", **kwargs):
"""
使用requests对网址发送请求,并将请求结果存储
:param url: 网址
:param path: 存储文件路径
:param encoding: 文件编码,默认utf-8
"""
response = requests.get(url, **kwargs)
if response.ok:
response.encoding = encoding
with open(path, "w", encoding=encoding) as f_w:
f_w.write(response.text
var cpro_id = "u6885494";











 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有